MtoM Mag - Le journal de l'MtoM.
- accueil .
- newsletter .
 Flux RSS .
Flux RSS . - soumissions .
- publicité .
- contacts
Flux RSS .
![]() Fivetran, le leader de l’intégration de données automatisée, annonce la publication de la deuxième édition de son benchmark annuel, qui compare les performances et les coûts des principales plates-formes de data warehouse du marché.
Fivetran, le leader de l’intégration de données automatisée, annonce la publication de la deuxième édition de son benchmark annuel, qui compare les performances et les coûts des principales plates-formes de data warehouse du marché.
Depuis 2012, la technologie de Fivetran transmet et synchronise des ensembles de données provenant d’applications, de bases de données et de répertoires de fichiers dans des data warehouses à des fins d’analytics. La question qui lui est le plus fréquemment posée par ses clients est Quel data warehouse dans le cloud dois-je choisir ? Afin de mieux répondre à cette question, la société réalise depuis 2019 un benchmark qui compare la vitesse et le coût des quatre plates-formes de data warehouse les plus populaires : Amazon RedShift, Snowflake, Presto et Google BigQuery.
Au cours des deux dernières années, les principaux data warehouses dans le cloud se sont rapprochés en termes de performances. RedShift et BigQuery ont tous deux fait évoluer leur expérience utilisateur pour la rapprocher de celle de Snowflake. Le marché converge aujourd’hui autour de deux principes : la séparation des traitements et du stockage, et une tarification au forfait, avec des ‘pics’ pour tenir compte de flux intermittents.
Un benchmark de data warehouses est avant tout une question de choix : quels types de données vais-je utiliser ? Dans quelle quantité ? Quels types de queries ? Ces choix ont des conséquences majeures. Il suffit de changer la nature des données ou la structure des queries, et le data warehouse le plus rapide pourra se retrouver en queue de peloton.
Dans son benchmark, Fivetran a choisi la configuration la plus proche de celle d’un utilisateur typique de sa solution, afin qu’il soit le mieux à même d’apprécier ses résultats.
Chaque data warehouse offre une expérience utilisateur et un modèle de tarification spécifiques. Les solutions testées peuvent être réparties sur le spectre ci-dessous, de ‘Self hosted’ (auto hébergé) à ‘Serverless’.
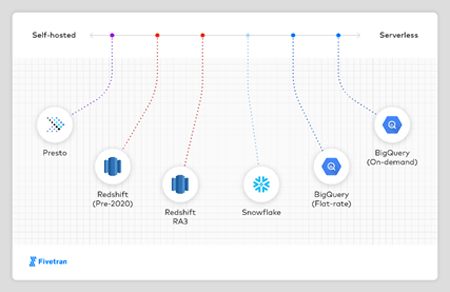
A l’extrême gauche du côté ‘Self hosted’ du spectre, on trouve Presto, qui laisse à l’utilisateur l’entière responsabilité de la fourniture des serveurs et de l’ensemble de la configuration du cluster. Presto est une solution open source, à la différence des autres systèmes présents dans le benchmark.
Pre RA3 RedShift intègre plus de fonctionnalités de gestion que Presto, mais exige toujours de l’utilisateur de configurer les clusters de traitement individuels avec un niveau déterminé de ressources mémoire, de traitement et de stockage.
RedShift RA3 rapproche RedShift de l’expérience utilisateur de Snowflake en séparant parties traitement et stockage.
Snowflake offre une expérience quasi ‘serverless’ : l’utilisateur configure la taille et le nombre des clusters de traitement. Chacun d’entre eux voit les mêmes données, et les clusters peuvent être créés et supprimés en quelques secondes. Snowflake propose plusieurs niveaux de tarification associés à des fonctionnalités différentes. Les calculs du benchmark sont basés sur le niveau le moins coûteux, ‘Standard’. Pour le niveau ‘Enterprise’ ou ‘Business Critical’, le coût sera 1,5 ou 2 fois plus élevé.
Le forfait de BigQuery est similaire à celui de Snowflake, excepté qu’il n’intègre pas le concept de cluster de traitement, mais uniquement un nombre configurable de ‘slots de traitement’.
BigQuery on demand est un pur modèle ‘serverless’, dans lequel l’utilisateur soumet ses ‘queries’ l’un après l’autre et paie par ‘query’. Le mode on demand peut être beaucoup plus coûteux ou beaucoup moins coûteux, en fonction de la nature du flux de données. Un flux « régulier » utilisant la capacité de traitement en 24/7 sera beaucoup moins cher en mode forfait. Un flux avec une succession de pointes contenant d’importants ‘queries’ entrecoupées de longues périodes d’inactivité sera beaucoup moins cher en mode on demand.
Tous les data warehouses testés offrent d’excellents niveaux de coût et de performance. Ce résultat n’est pas étonnant, car les techniques de base pour construire un data warehouse en cylindres performant sont bien connues depuis la publication de l’article C Store en 2005. Toutes les solutions utilisent donc les mêmes recettes standard pour optimiser leurs performances : stockage en cylindres, planification des ‘queries’ basée sur les coûts, exécution par pipeline et compilation juste à temps.
Les principales différences entre les plates-formes testées sont donc au niveau qualitatif, en raison de choix de conception différents. Certaines mettent en avant les capacités de configuration et de réglage, d’autres la simplicité d’utilisation. La meilleure stratégie pour les entreprises est donc de tester plusieurs solutions, et de choisir celle qui offre le meilleur équilibre correspondant à ses besoins.


